author = {Karpinska, Marzena and Li, Bofang and Rogers, Anna and Drozd, Aleksandr},
title = {Subcharacter {{Information}} in {{Japanese Embeddings}}: {{When Is It Worth It}}?},
booktitle = {Proceedings of the {{Workshop}} on the {{Relevance}} of {{Linguistic Structure}} in {{Neural Architectures}} for {{NLP}}},
publisher = {{Association for Computational Linguistics}},
address = {Melbourne, Australia},
url = {http://aclweb.org/anthology/W18-2905},
year = {2018},
pages = {28-37}
}
The Japanese Bigger Analogy Test Set (jBATS)
Word analogy task has been one of the standard benchmarks for word embeddings since the striking demonstration of “linguistic regularities” by Mikolov et al. (2013) 1. Their big finding was that linear vector offsets seem to mirror linguistic relations, and can be used to perform analogical reasoning.
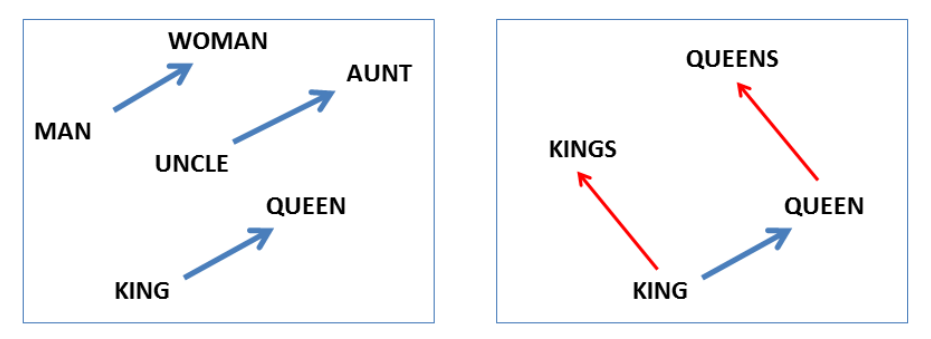
Figure 1. Linear vector offsets as model of linguistic relations (Mikolov et al., 2013) 1
For example, consider a pair of words a : a' :: b : b such as man: woman :: king : queen. Mikolov et al. proposed that the b' word could be found with the help of the offset between the word vectors b and a. In this case, the word vector queen should be the vector that is the closest to the result of calculation king - man + woman.
Mikolov et al. demonstrated their findings on the Google analogy dataset, which consists of 9 morphological and 5 semantic categories, with 20-70 unique word pairs per category: 8,869 semantic and 10,675 syntactic questions in total. However, this set was unbalanced, and some categories were overrepresented (particularly the country:capital relation constituted over 50% of all word pairs in the semantic category). Gladkova et al. (2016) proposed BATS (The Better Analogy Test Set), which covers eaqually derivational and inflectional morphology, as well as lexicographic and encyclopedic semantics. Each of these relations consists of 10 categories and each of the categories is being represented by 50 unique word pairs giving a total of 99,200 questions 3 for the vector offset method.
What is jBATS?
jBATS was designed based on BATS and is, to our best knowledge, the first analogy test set for Japanese. Similarly to BATS it features 4 linguistcs relations: (1) derivational morphology, (2) inflectional morphology, (3) lexicographic semantics, and (4) encyclopedic semantics.
jBATS was structured to be:
balanced and representative - similarly to BATS, jBATS also offers 4 linguistics relations, each of which consists of 10 categories featuring 50 distinguish pairs (with an exception of the city:prefecture pairing, which contains 47 pairs since there are only 47 prefectures). This gives a total of 97,712 questions for the vector offset method.
tokenization friendly - all the pairs were desinged so that they can be used with a MeCab-like tokenization. Pairs, in which tokenization could introduce ambiguity, were avoided.
frequency balanced - the mean of frequencies from the Balance Corpus of Conterprorary Written Japanese and the Mainichi Newspaper corpus were computed and only items with mean frequencies between 1,000 and 10,000 were chosen, whenever possible.
alternative spelling - the correct answers are provided in both kanji and hiragana/katakana forms. For example, 出す is being represented as 出す and だす.
multiple correct answers - similarly to BATS, jBATS is not penalizing the model for the complicity of human language. For example, 服, アパレル and お召し物 will all be listed among others as hypernyms of スカート.
| Subcategory | Relations | Subcategory | Relations | ||
Morphology (inflections) |
verbs | I01: u-form > a-form (書く : 書か) | Semantics (lexicography) |
hypernyms | L01: animals (カニ : 甲殻類 / こうかくるい / ...) |
| I02: u-form > o-form (受ける : 受けよ) | L02: miscellaneous (椅子 : 家具 / かぐ / ...) | ||||
| I03: u-form > e-form (起きる : 起きれ) | hyponyms | L03: miscellaneous (肉 : 牛肉 / ぎゅうにく / ...) | |||
| I04: u-form > te-form (会う : 会っ) | meronyms | I04: substance (バッグ : 革 / かわ / ...) | |||
| I05: a-form > o-form (書か : 書こ) | L05: member (メンバー : クラブ / チーム / ...) | ||||
| I06: o-form > e-form (歌お:歌え) | L06: part-whole (魚 : フィン / 骨 / ...) | ||||
| I07: e-form > te-form (勝て:勝っ) | synonyms | L07: intensity (怖い : 恐ろしい / おそろしい / ...) | |||
| i-adjectives | I08: i-form > ku-form (良い:良く) | L08: exact (言う : 述べる / のべる / ...) | |||
| I09: i-form > ta-form (良い:良かっ) | antonyms | L09: gradable (強い : 弱い / よわい / ...) | |||
| I10: ku-form > ta-form (良く:良かっ) | L10: binary (大きい : 小さい / ちいさい) | ||||
Morphology (derivation) |
suffix | D01: na-adj. + 化(活性:活性化) | Semantics (encyclopedia) |
geography | E01: capitals (ロンドン : イギリス / 英国 / えいこく / ...) |
| D02: i-adj. + さ (良い:良さ) | E02: country:language (韓国 : 韓国語 / かんこくご) | ||||
| D03: noun + 者 (消費:消費者) | E03: city:prefecture (秩父 : 埼玉県) | ||||
| D04: noun + 会 (運動:運動会) | people | E04: nationalities (ショパン : ポーランド人 / ポーランドじん) | |||
| D05: noun/na-adj.+ 感 (存在:存在感) | E05: occupation (アリストテレス : 哲学者 / てつがくしゃ / ...) | ||||
| D06: noun/na-adj.+ 性 (可能:可能性) | other | E06: company:product (日産 : 自動車 / じどうしゃ / ...) | |||
| D07: noun/na-adj.+ 力 (影響:影響力) | E07: onomatopoeia:feeling (イライラ : 嫌悪 / けんお / ...) | ||||
| prefix | D08: 不 + noun (十分:不十分) | E08: thing:color (あざ : 青 / あお / ...) | |||
| D09: 大 + noun/na-adj. (好き:大好き) | E09: object:usage (ギター : 弾く / ひく / ...) | ||||
| other | D10: (in)transitive verb (落ちる:落とす) | E10: polite terms (言う : おっしゃる / ...) |
Performance on jBATS
jBATS was initially used to evaluate the performance of the subcharacter and character level models in Japanese 6. These models take advantage of the information in Chinese characters - kanji (SG + kanji) and their components, called bushu (SG + kanji + bushu). The overall performance of both models was compared with the traditional Skip-Gram model (SG) and FastText.
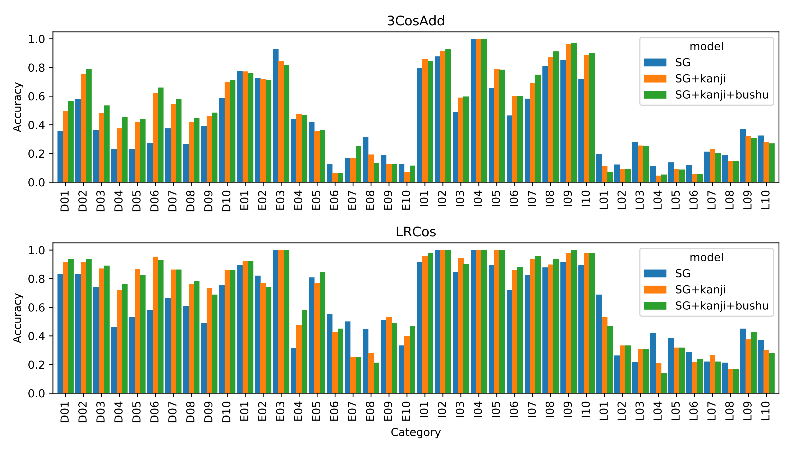
Figure 2. Performance on jBATS: SG, SG + kanji, and SG + kanji + bushu as measure by the 3CosAdd (upper figure) and LRCos (lower figure) methods.
Including the bushu information has proven to be beneficial especially for the inflectional and derivational relations, where most tokens were written using a single kanji or a kanji affix, related to the word meaning. The smallest improvement was observed for the lexicographic semantics categories, where traditional Skip-Gram model performed better in most cases. Semantic relations were also the most difficult to capture, which is consistent with the finidings for English in Gladkova et al. (2016) 2 and Drozd et al. (2016) 4. Moreover, the LRCos method 4 yielded overall better results than 3CosAdd achieving up to over 36% better accuracy, which was also shown for English in Drozd et al. (2016) 4. The overall accuracy on word analogy task (LRCos method) of all the models (including FastText) for different corpus size can be found in Karpinska et al. (2018) 6
Footnotes
- 1(1,2)
-
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL-HLT 2013 (pp. 746–751). Atlanta, Georgia, 9–14 June 2013. Retrieved from https://www.aclweb.org/anthology/N13-1090
- 2
-
Gladkova, A., Drozd, A., & Matsuoka, S. (2016). Analogy-based detection of morphological and semantic relations with word embeddings: what works and what doesn’t. In Proceedings of the NAACL-HLT SRW (pp. 47–54). San Diego, California, June 12-17, 2016: ACL. https://www.aclweb.org/anthology/N/N16/N16-2002.pdf
- 3
-
The abstract of the original paper has a mistake: the total number of questions in BATS is 99,200.
- 4(1,2,3)
-
Drozd, A., Gladkova, A., & Matsuoka, S. (2016). Word embeddings, analogies, and machine learning: beyond king - man + woman = queen. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (pp. 3519–3530). Osaka, Japan, December 11-17. https://www.aclweb.org/anthology/C/C16/C16-1332.pdf
- 5
-
Rogers, A., Drozd, A., & Li, B. (2017). The (Too Many) Problems of Analogical Reasoning with Word Vectors. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (* SEM 2017) (pp. 135–148). http://www.aclweb.org/anthology/S17-1017
- 6(1,2)
-
Karpinska, M., Li, B., Rogers, A., & Drozd, A. (2018) Subcharacter information in Japanese embeddings: when is it worth it? In In Proceedings of the Workshop on Relevance of Linguistic Structure in Neural Architectures for NLP (RELNLP) 2018, to appear. ACL, 2018.