author = {Gladkova, Anna and Drozd, Aleksandr and Matsuoka, Satoshi},
title = {Analogy-Based Detection of Morphological and Semantic Relations with Word Embeddings: What Works and What Doesn't},
booktitle = {Proceedings of the NAACL-HLT SRW,
address = {San Diego, California, June 12-17, 2016},
publisher = {ACL},
year = {2016},
pages = {47-54}
doi = {10.18653/v1/N16-2002},
url = {https://www.aclweb.org/anthology/N/N16/N16-2002.pdf},
}
The Bigger Analogy Test Set (BATS)
Word analogy task has been one of the standard benchmarks for word embeddings since the striking demonstration of “linguistic regularities” by Mikolov et al. (2013) 1. Their big finding was that linear vector offsets seem to mirror linguistic relations, and can be used to perform analogical reasoning.
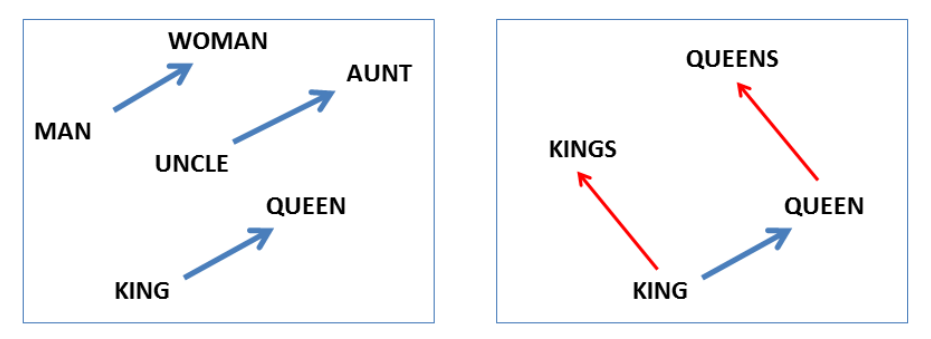
Figure 1. Linear vector offsets as model of linguistic relations (Mikolov et al., 2013) 1
For example, consider a pair of words a : a' :: b : b such as man: woman :: king : queen. Mikolov et al. proposed that the b' word could be found with the help of the offset between the word vectors b and a. In this case, the word vector queen should be the vector that is the closest to the result of calculation king - man + woman.
Why BATS is different
Mikolov et al. demonstrated their findings on a dataset of the Google analogy dataset that had 9 morphological and 5 semantic categories, with 20-70 unique word pairs per category: 8,869 semantic and 10,675 syntactic questions in total.
These numbers look convincingly large, but language has thousands of relations of various kinds, and human analogical reasoning does not just use one rule for all cases. The Google test set had only 15 relations, and was also highly unbalanced. 56.72% of all semantic questions are from the same famous country:capital category, and "syntactic" questions were mostly on inflectional rather than derivational morphology.
BATS 2 is an improvement over this dataset in several aspects:
balanced and representative: BATS covers inflectional and derivational morphology, and lexicographic and encyclopedic semantics. Each relation is represented with 10 categories, and each category contains 50 unique word pairs. This makes for 98,000 3 questions for the vector offset method.
reduced homonymy: the morphological categories were sampled to reduce homonymy. For example, for verb present tense the Google set includes pairs like walk:walks, which could be both verbs and nouns.
multiple correct answers where applicable. For example, both mammal and canine are hypernyms of dog. In some cases alternative spellings are listed (e.g. organize: reorganize/reorganise).
| Subcategory | Relations | Subcategory | Relations | ||
Morphology (inflections) |
nouns | I01: regular plurals (student:students) | Semantics (lexicography) |
hypernyms | L01: animals (cat:feline) |
| I02: plurals - orthographic changes (wife:wives) | L01: miscellaneous (plum:fruit, shirt:clothes) | ||||
| adjectives | I03: comparative degree (strong:stronger) | hyponyms | L01: miscellaneous (bag:pouch, color:white) | ||
| I04: superlative degree (strong:strongest) | meronyms | I04: substance (sea:water) | |||
| verbs | I05: infinitive: 3ps.sg (follow:follows) | L01: member (player:team) | |||
| I06: infinitive: participle (follow:following) | L06: part-whole (car:engine) | ||||
| I07: infinitive: past (follow:followed) | synonyms | L01: intensity (cry:scream) | |||
| I08: participle: 3ps.sg (following:follows) | L08: exact (sofa:couch) | ||||
| I09: participle: past (following:followed) | antonyms | L09: gradable (clean:dirty) | |||
| I10: 3ps.sg : past (follows:followed) | L01: binary (up:down) | ||||
|
Morphology (derivation)
|
no stem change |
D01: noun+less (life:lifeless) | Semantics (encyclopedia) |
geography | E01: capitals (athens:greece) |
| D02: un+adj. (able:unable) | E02: country:language (bolivia:spanish) | ||||
| D03: adj.+ly (usual:usually) | E03: uk city:county (york:yorkshire) | ||||
| D04: over+adj./ved (used:overused) | people | E04: nationalities (lincoln:american) | |||
| D05: adj.+ness (same:sameness) | E01: occupation (lincoln:president) | ||||
| D06: re+verb (create:recreate) | animals | E06: the young (cat:kitten) | |||
| D07: verb+able (allow:allowable) | E07: sounds (dog:bark) | ||||
| stem change |
D08: verb+er (provide:provider) | E08: shelter (fox:den) | |||
| D09: verb+ation (continue:continuation) | other | E09: thing:color (blood:red) | |||
| D10: verb+ment (argue:argument) | E10: male:female (actor:actress) |
Performance on BATS
The initial results with BATS were striking: GloVe 4, the model that claimed over 80% accuracy on the Google syntactic analogies, achieved under 30% on BATS. Furthermore, only inflectional morphology categories can be reliably detected, and the famous country:capital category is a clear outlier among the semantic categories, most of which have very low accuracy.
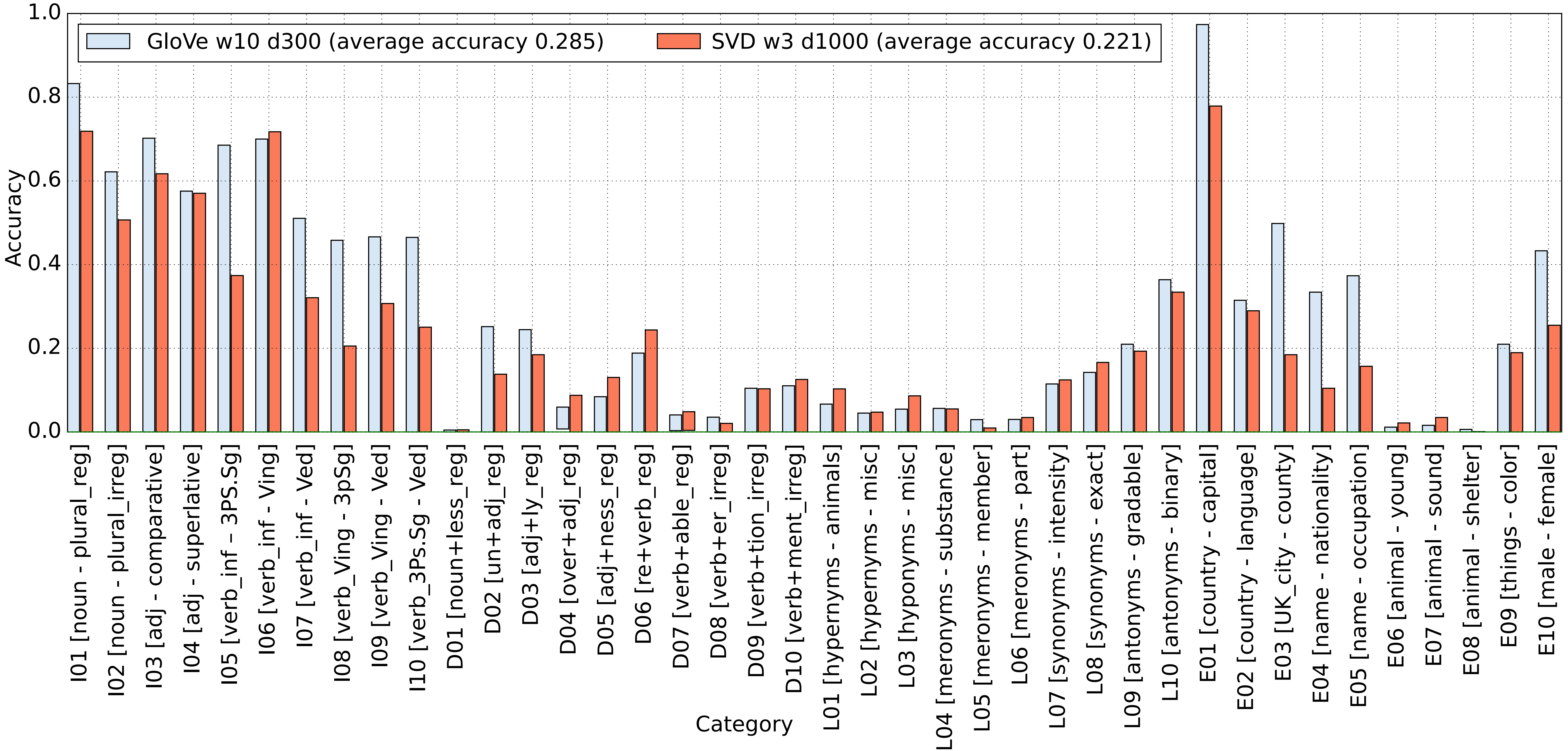
Figure 2. Performance on BATS: GloVe word embeddings vs count-based vectors condensed with SVD
Interestingly, the above figure also shows that GloVe is generally not that different from a traditional count-based SVD: although it performs slightly better in many cases, the overall pattern of categories that are easy/difficult is clearly the same for both models. The same pattern was confirmed in a subsequent study 5.
BATS thus presents more of a challenge to the modern systems that make use of word embeddings for verbal reasoning tasks. To the best of our knowledge, no system has yet achieved over 50% accuracy on the whole BATS, although there were several significant improvements:
subword-level models such as Fasttext achieve much higher accuracy on derivational morphology, as compared to the word-level models such as SkipGram 6 .
the vector offset method is not the best way to solve word analogies, with LRCos method achieving up to 35% improvement in some categories 5 ;
Future work should take into account that all the current methods are heavily biased by cosine similarity between the source words, which means that the results on word analogy task indicate which relations a given model favors in vector neighborhoods (and not some general "goodness" of the model) 7 .
A comparable dataset for Japanese is now also available. It was used to show the effectiveness of leveraging subcharacter information to produce more meaningful representations for Japanese characters.
Footnotes
- 1(1,2)
-
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL-HLT 2013 (pp. 746–751). Atlanta, Georgia, 9–14 June 2013. Retrieved from https://www.aclweb.org/anthology/N13-1090
- 2
-
Gladkova, A., Drozd, A., & Matsuoka, S. (2016). Analogy-based detection of morphological and semantic relations with word embeddings: what works and what doesn’t. In Proceedings of the NAACL-HLT SRW (pp. 47–54). San Diego, California, June 12-17, 2016: ACL. https://www.aclweb.org/anthology/N/N16/N16-2002.pdf
- 3
-
The original paper has a typo: the total number of questions in BATS is 98,000, not 99,200.
- 4
-
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Vol. 12, pp. 1532–1543). https://www.aclweb.org/anthology/D14-1162
- 5(1,2)
-
Drozd, A., Gladkova, A., & Matsuoka, S. (2016). Word embeddings, analogies, and machine learning: beyond king - man + woman = queen. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (pp. 3519–3530). Osaka, Japan, December 11-17. https://www.aclweb.org/anthology/C/C16/C16-1332.pdf
- 6
-
Li, B., Drozd, A., Liu, T., & Du, X. (n.d.). Subword-level Composition Functions for Learning Word Embeddings. In Proceedings of the Second Workshop on Subword/Character LEvel Models (pp. 38–48). New Orleans, Louisiana, June 6, 2018. http://www.aclweb.org/anthology/W18-1205
- 7
-
Rogers, A., Drozd, A., & Li, B. (2017). The (Too Many) Problems of Analogical Reasoning with Word Vectors. In Proceedings of the 6th Joint Conference on Lexical and Computational Semantics (* SEM 2017) (pp. 135–148). http://www.aclweb.org/anthology/S17-1017