Japanese Subword-level word embeddings
Languages with logographic writing systems present a difficulty for traditional character-level models. Leveraging the subcharacter information was recently shown to be beneficial for a number of intrinsic and extrinsic tasks in Chinese 1 2 3. We examine whether the same strategies could be applied for Japanese.
In scope of this work, we also developed a new analogy dataset (jBATS) for Japanese, and contributed new versions of its only similarity dataset (jSIM). Our implementation is available in the Vecto library.
The bushu information was injected by pre-processing the training corpora, as shown in Figure 1. Each complex character was prepended a list of its components, according to KanjiGlyph database
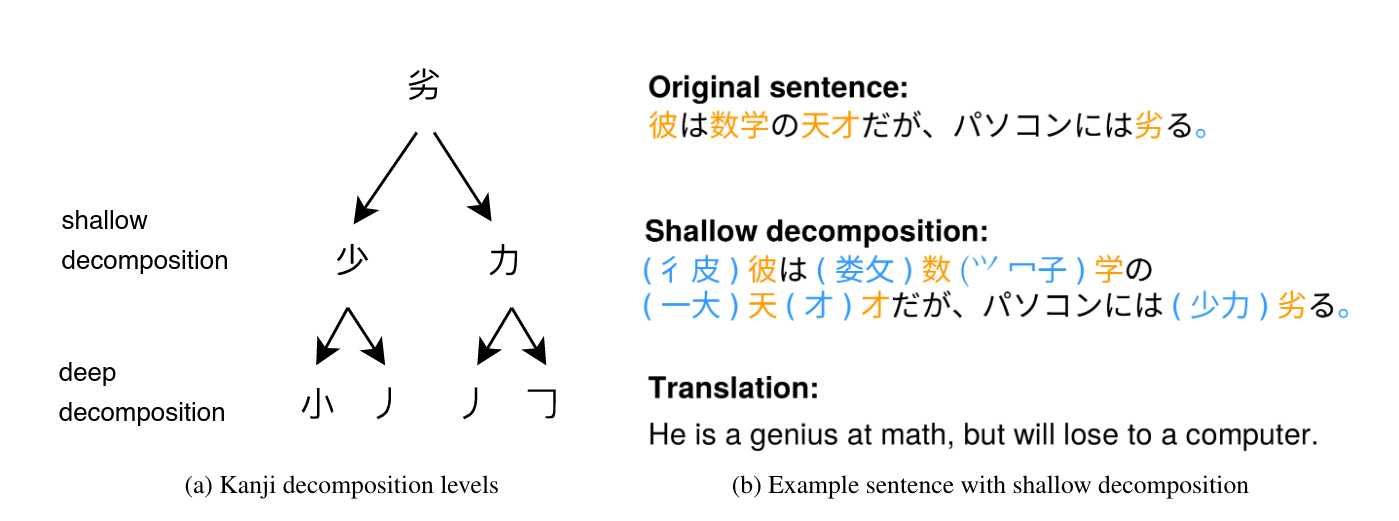
Figure 1. Incorporating subcharacter information in Japanese.
The overall architecture of Japanese embedding models are shown in Figure 1.
The original SG (Skip-Gram) 4 model (Figure 1-a) uses only word-level information.
SG+kanji model (Figure 1-b) is a special case of FastText 5, where the minimal n-gram size and maximum n-gram size are both set to $1$. This enables us to take individual kanji into account.
SG+kanji+bushu (Figure 1-c) model sums the vector of the target word, its constituent characters, and their constituent bushu to incorporate the bushu information. For example, the vector of the word 仲間, the vectors of characters 仲 and 間, and the vectors of bushu 亻, 中, 門, 日 are summed to predict the contextual words.
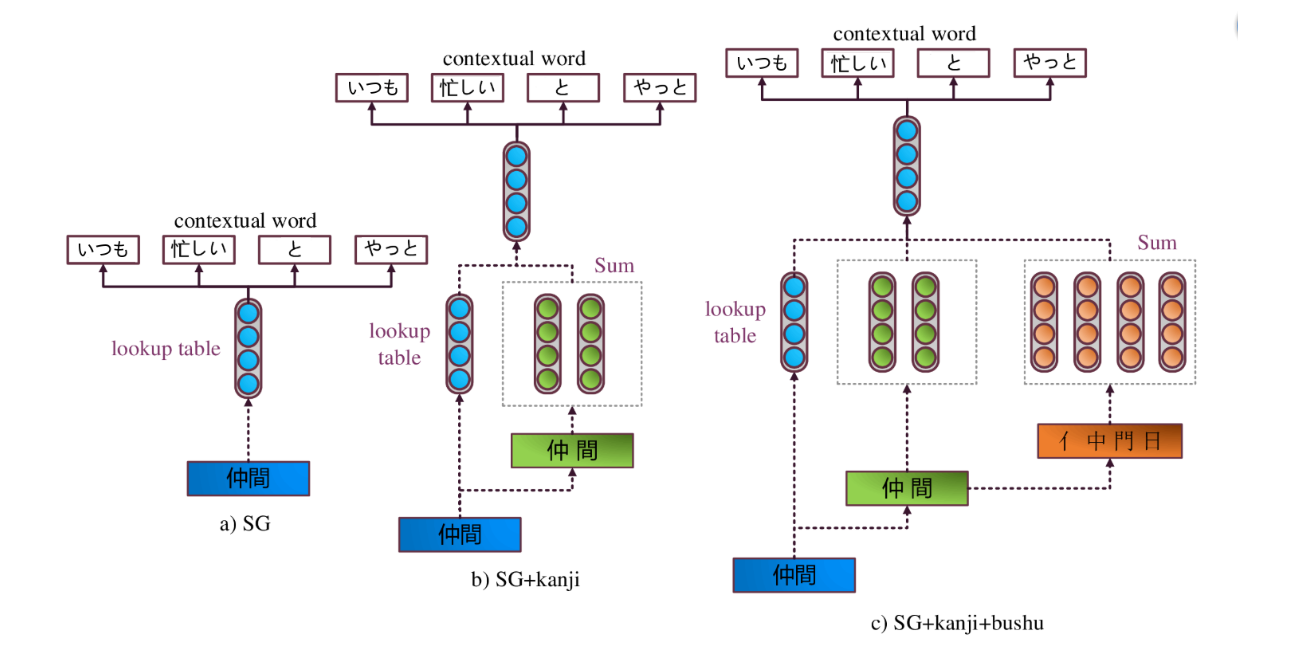
Figure 2. Model architecture of SG, SG+kanji, and SG+kanji+bushu 6 . Example sentence: いつも~~忙しい~~仲間~~と~~やっと~~会え~~た (I have finally met with my busy colleague.), window size 2.
Results: subcharacter information does help to construct OOV representations
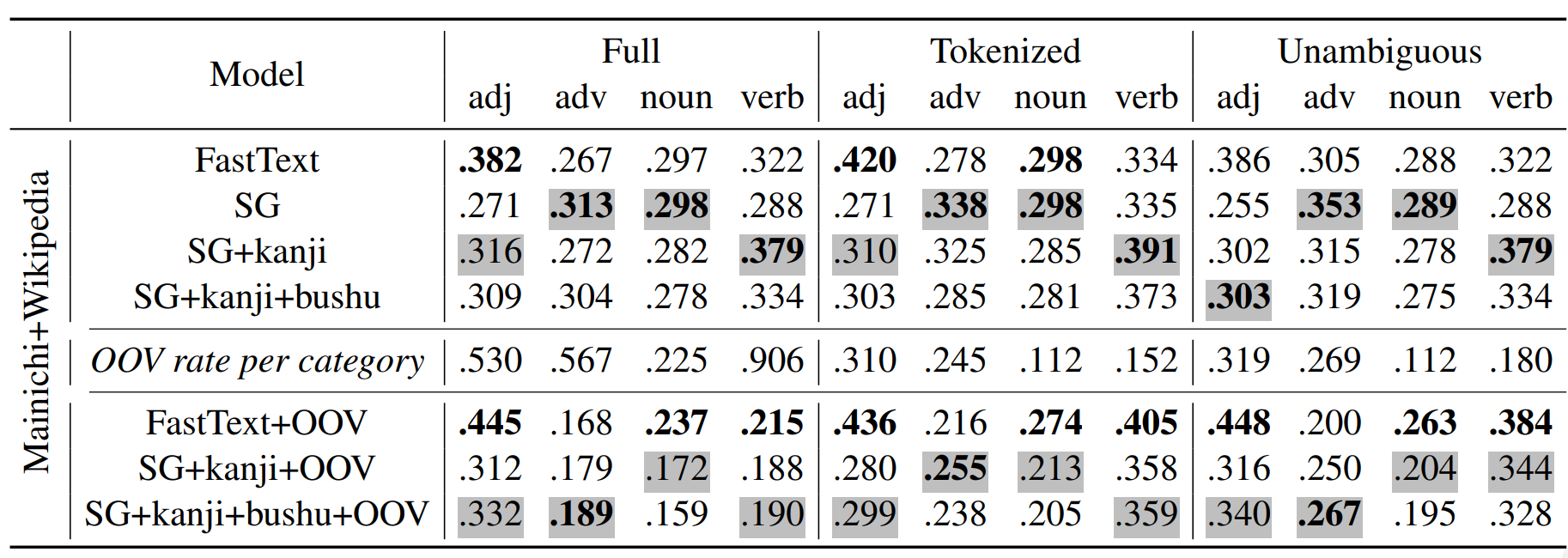
Table 1. Spearman's correlation with human similarity judgements.
Table 1 shows the results on word similarity task (jSIM). Models are trained on the full Mainichi corpus 7, a half Mainichi corpus, and Wikipedia. The strongest effect for inclusion of bushu is observed in the OOV condition: in all datasets the Spearman's correlations are higher for SG+kanji+bushu than for other SG models, which suggests that this information is indeed meaningful and helpful. The gains are also the most consistent for the adjective category, which has the highest percentage of single-kanji words. Multiple-kanji words may contain kanjis that are irrelevant to the meaning of the whole word, and that could be expected to increase the noise for bushu-aware models.
Results: subcharacter information is helpful for morphological task
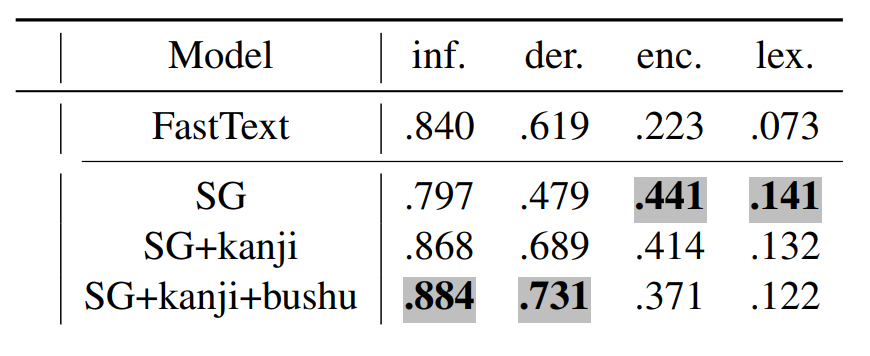
Table 2. Word analogy task accuracy (LRCos).
Table 2 shows the results on 4 categories of word analogy task (jBATS). The morphology categories behave similarly to adjectives in the similarity task: the SG+kanji beats the original SG by a large margin on inflectional and derivational morphology categories, and bushu improve accuracy even further. However, like with the similarity task, note that these are the categories in which the task is to identify a single kanji with a clear semantic role in the compound. In semantic categories, vanilla SG has a clear advantage.
At the same time, in both experiments, the FastText model performs comparably or better with the subcharacter models, which suggests the need for re-evaluation of the previous results for Chinese that did not explicitly compare with FastText.
Implementation
We implement all the subword-level models using Chainer deep learning framework.
Sample script for training Japanese word-level word embeddings (SG):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword none --language jap
Sample script for training Japanese subword-level word embeddings (SG+kanji):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword sum --language jap
Sample script for training Japanese subword-level word embeddings (SG+kanji+bushu):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword sum --language jap --path_word2chars path_word2chars
Footnotes
- 1
-
Yaming Sun, Lei Lin, Nan Yang, Zhenzhou Ji, and Xiaolong Wang. 2014. Radical-Enhanced Chinese Character Embedding. In Neural Information Processing, Lecture Notes in Computer Science, pages 279–286. Springer, Cham. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.752.2770&rep=rep1&type=pdf
- 2
-
Yanran Li, Wenjie Li, Fei Sun, and Sujian Li. 2015. Component-enhanced Chinese character embeddings. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 829–834, Lisbon, Portugal, 17-21 September 2015. Association for Computationa lLinguistics. http://anthology.aclweb.org/D/D15/D15-1098.pdf
- 3
-
Frederick Liu, Han Lu, Chieh Lo, and Graham Neubig. 2017. Learning Character-level Compositionality with Visual Features. pages 2059–2068. Association for Computational Linguistics. http://www.aclweb.org/anthology/P17-1188
- 4
-
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL-HLT 2013 (pp. 746–751). Atlanta, Georgia, 9–14 June 2013. Retrieved from https://www.aclweb.org/anthology/N13-1090
- 5
-
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146. http://www.aclweb.org/anthology/Q17-1010
- 6
-
Karpinska, M., Li, B., Rogers, A., & Drozd, A. (2018) Subcharacter information in japanese embeddings: when is it worth it? In Proceedings of the Workshop on Relevance of Linguistic Structure in Neural Architectures for NLP (RELNLP) 2018, to appear. ACL, 2018.
- 7
-
Nichigai Associate. 1994-2009. CD-Mainichi Shimbun de-ta shu (1994-2009).