Paper (the original)
Test scripts
author = {Karpinska, Marzena and Li, Bofang and Rogers, Anna and Drozd, Aleksandr},
title = {Subcharacter {{Information}} in {{Japanese Embeddings}}: {{When Is It Worth It}}?},
booktitle = {Proceedings of the {{Workshop}} on the {{Relevance}} of {{Linguistic Structure}} in {{Neural Architectures}} for {{NLP}}},
publisher = {{Association for Computational Linguistics}},
address = {Melbourne, Australia},
url = {http://aclweb.org/anthology/W18-2905},
year = {2018},
pages = {28-37}
}
The Revised Similarity Dataset for Japanese (jSIM)
The dataset for the word similarity task consists of pairs of words evaluated by human annotators in terms of their similarity. Similarity in general is a concept difficult to fully grasp and define. Therefore, the rating process may be challenging and the ratings may be somewhat misleading. Nevertheless, word similarity task, though controversial, remains a widely used method to evaluate word embeddings. The Japanese Word Similarity Dataset 1 is by far the only similarity dataset for the Japanese language. Pairs in this set were divided by part-of-speech into four categories: nouns, adjectives, verbs, and adverbs. Since the set was created based on a paraphrasing dataset a lot of phrases were also introduced. There are, however, two main problems with that approach: (1) the part-of-speech in Japanese is not always straightforward, and (2) Japanese tokenization introduces a lot of ambiguity and makes phrase processing impossible. Therefore, we have decided to recategorize the existing dataset and make it more tokenization-friendly, so that it can be used on a tokenized corpus.
Recategorizings POS
One of the challenges with Japanese language is that words can somewhat "move" from one part-of-speech category to another as a biproduct of conjugation. For example, the verb 働く ("to work") becomes 働きたい ("want to work"), which will then behave like an adjective. Therefore, categorizing conjugated words can pose a challenge and raise a discussion among linguists. Moreover, the traditional tokenization method invites a certain ambiguity. For example a negation of an adjective like 早くない is being split into 早く and ない, where the first part can be also treated as an adverb. There is no way of knowing if the item in question was initially an adjective or an adverb only by looking at the tokenized pair of words. Regardless of the possible challenges mentioned above the original dataset contained a number of pairs, which were simply misclassified or were a mix of words from two different categories. We redesigned the original set by moving those misclassified pairs into the right categories (2-5% of all pairs) and keeping the mix pairs as a separate category. We decided to keep the "ku-form" of adjectives in the adjective category, even though it may also come from an adverb. For that reason, it was excluded from the narrow, tokenization-friendly version of this dataset, which is described below (unambiguous version).
Introducing the tokenization-friendly dataset
Traditional Japanese tokenization can be very ambiguous and misleading. Basic information, such as past tense or negation are usually lost and phrases are beyond recognition. This may invite plenty of ambiguity into the similarity task and produce misleading results. Therefore, we decided to further process the Japanese Word Similarity Dataset in order minimalize the ambiguity created during the tokenization process.
We present jSIM - a recategorized version of the original dataset, which comes in three different flavors:
full version: the orginal dataset with recategorized pairs.
tokenized version: a subset of the "full version" containing only words, which could be still recognized after a MeCab-like tokenization. This version contains also words like 帰っ which may come from 帰った, 帰って, 帰ったり and so on, all of these being a certain form of the verb 帰る.
unambiguous version: a subset of the "tokenized version" containing only words that can be recognized and are unambiguous.
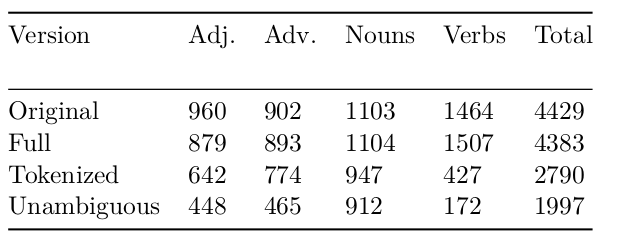
Table 1. The size of the original and modified Japanese similarity datasets (in word pairs).
Preformance on jSIM
We use all three versions of jSIM to evaluate the performance of the subcharacter and character level models in Japanese 2. These models take advantage of the information in Chinese characters - kanji (SG + kanji) and their components, called bushu (SG + kanji + bushu). The overall performance of both models was compared with the traditional Skip-Gram model (SG) and FastText.
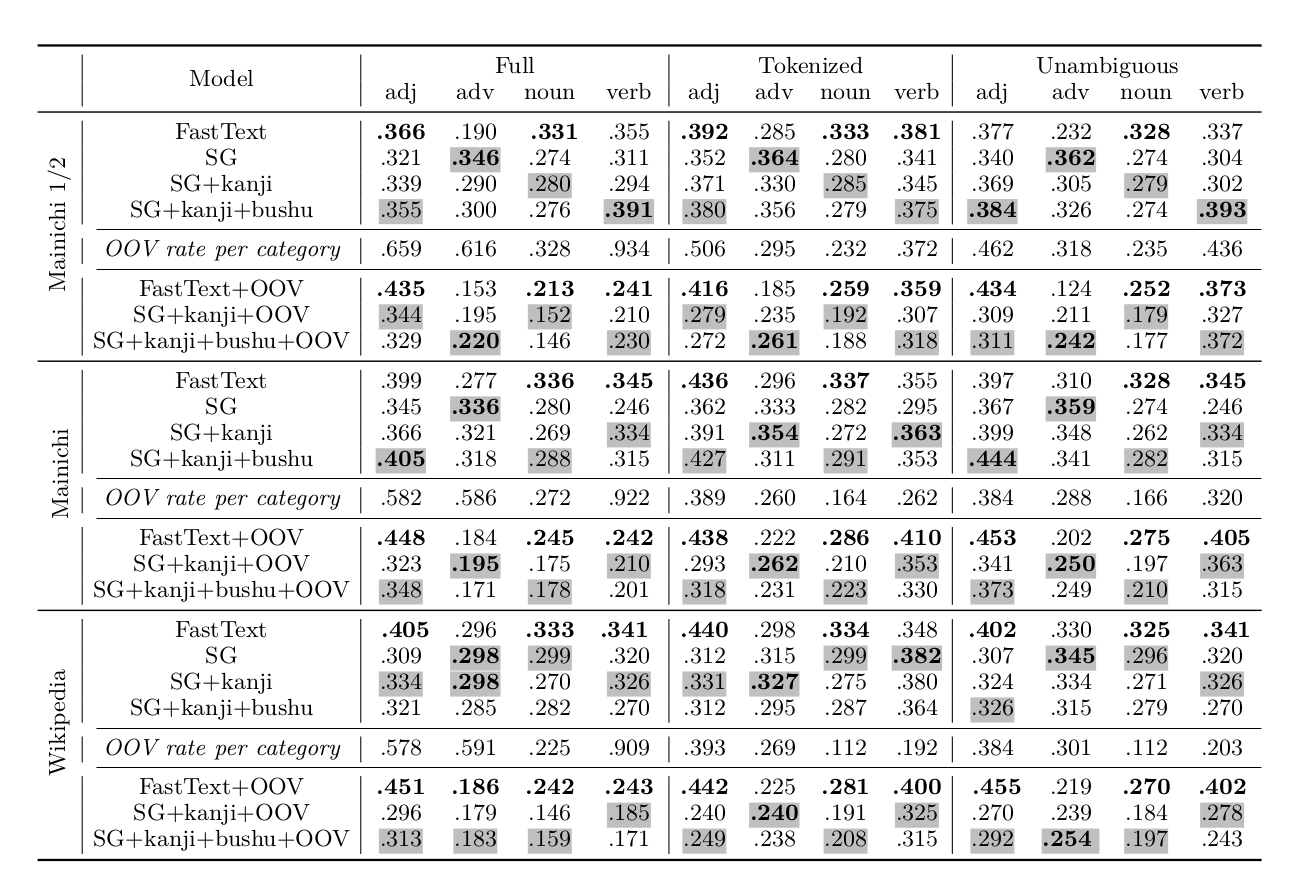
Table 2. Spearman correlation with human similarity judgements. Boldface indicates the highest result on a given corpus (separately for in-vocabulary and OOV conditions). Shaded numbers indicate the highest result among the three Skip-Gram models.
Table 2 shows the results on all 3 datasets on all models, trained on the full Mainichi corpus, a half Mainichi corpus, and Wikipedia. The strongest effect for inclusion of bushu is observed in the OOV condition: in all datasets the Spearman correlations are higher for SG+kanji+bushu than for other SG models, which suggests that this information is indeed meaningful and helpful. This even holds for the full version, where up to 90% vocabulary is missing and has to be composed. For in-vocabulary condition this effect is noticeably absent in Wikipedia (perhaps due to the higher ratio of names, where the kanji meanings are often irrelevant). However, in most cases the improvement due to inclusion of bushu, even when it is observed, is not sufficient to catch up with the FastText algorithm, and in most cases FastText has substantial advantage.
Footnote
- 1
-
Yuya Sakaizawa and Mamoru Komachi. 2017. Construction of a Japanese Word Similarity Dataset. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- 2
-
Karpinska, M., Li, B., Rogers, A., & Drozd, A. (2018) Subcharacter information in Japanese embeddings: when is it worth it? In In Proceedings of the Workshop on Relevance of Linguistic Structure in Neural Architectures for NLP (RELNLP) 2018, to appear. ACL, 2018.