Subword-level word embeddings
Subword-level information is crucial for capturing morphology and improving compositional representations for out-of-vocabulary entries. We propose CNN- and RNN-based subword-level word embedding models, which considerably outperform Skip-Gram 1 and FastText 2 on morphology-related tasks. Figure 1 shows the architecture of our models in comparison with the original Skip-Gram and FastText. Our implementation is available in the Vecto library.
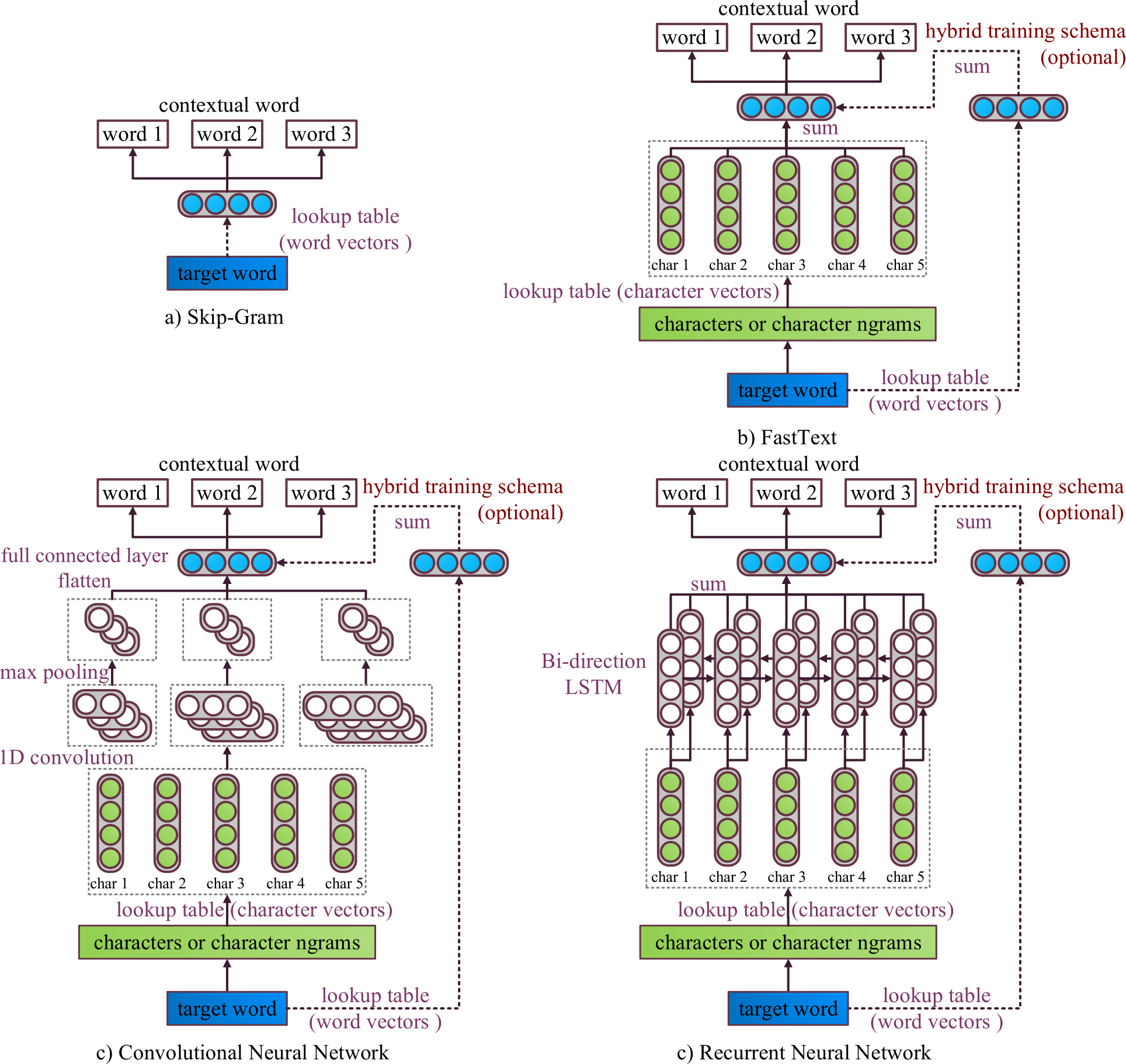
Figure 1. Illustration of original Skip-Gram and subword-level models. (Li et al., 2018) 3
Compared to FastText, our CNN- and RNN-based subword-level word embedding models use neural network instead of simple summation. We also propose a hybrid training scheme, which makes these neural networks directly integrated into Skip-Gram model. We train two sets of word embeddings simultaneously:
one from a lookup table as in traditional Skip-Gram,
one from convolutional or recurrent neural network.
We hypothesize that the former is better at capturing distributional similarity, which is mirroring semantic similarity. The latter should be more focused on morphology and can be used to create embeddings for OOV words.
Results: better recognition of different derivation categories
Figure 2 shows a t-SNE projection of the words with different affixes. It is clear that both CNN- and RNN-based models are able to distinguish different derivation types, and predict which affix is present in a morphologically complex word.
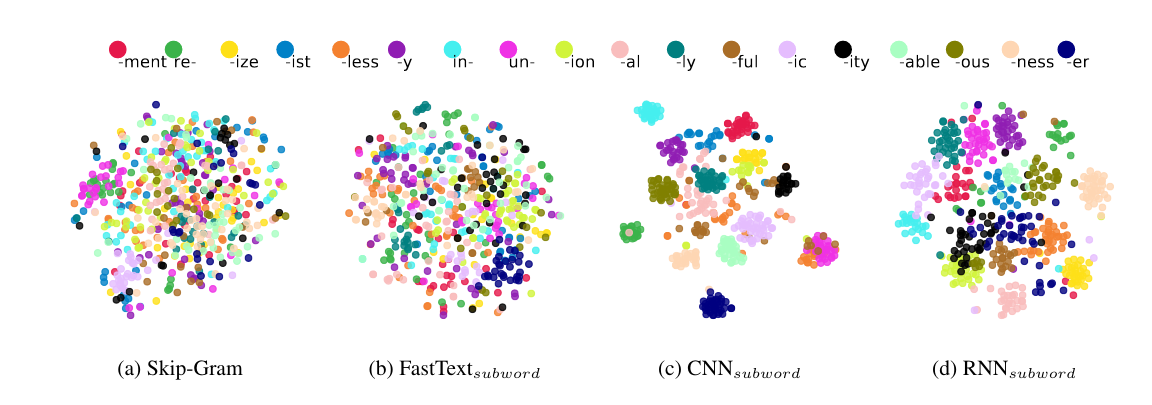
Figure 2. Visualization of learned word embeddings, each dot represents a word, different colors represent different affixes.
Results: improved performance on morphological word analogies
We test our models on the standard word similarity and analogy tasks, including the (BATS) dataset that provides a balanced selection of analogy questions in inflectional and derivational morphology categories.
We find that the morphological component is getting a significant boost, as shown by performance on the inflectional and derivational morphology categories of BATS. It is especially obvious on derivation morphology category, where Skip-Gram only achieves 9.6% accuracy and subword-level models achieve minimal 57.8% accuracy (excluding the lookup table versions). Our best subword models achieve up to 12% advantage over a comparable FastText model.
Since our CNNsubword and RNNsubword models are more focused on word morphology, they could be expected to not perform well on word similarity task. However, we find that the versions of our CNN and RNN models with vector lookup table achieve comparable or even better results on semantic tasks as the Skip-Gram model. Thus our models maintain the semantic aspects of the representations while considerably enhancing their morphological aspects.
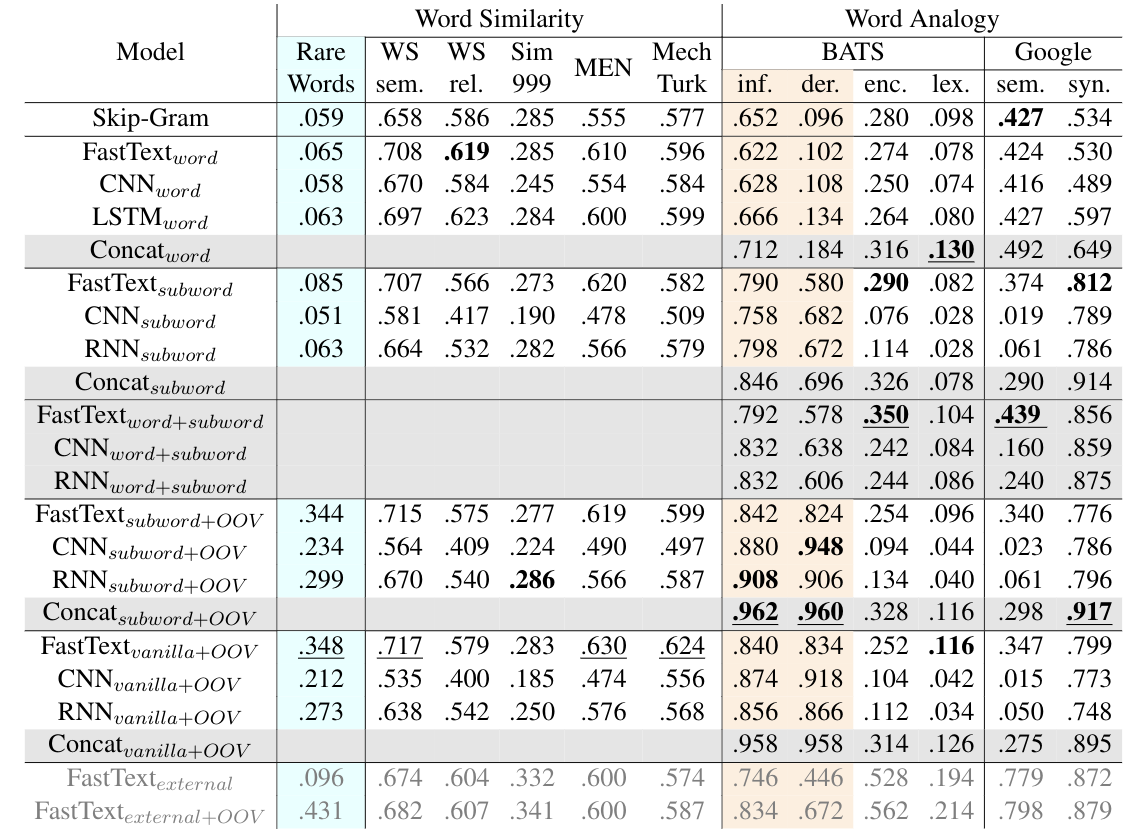
Table 1. Results on word similarity and word analogy datasets. Model combinations are denoted as gray rows, and best results among them are marked Bold. Morphology related categories are denoted as almond columns.
For hybrid training scheme, we denote the embeddings that come from word vector lookup table as "Modelword", and the embeddings which come from the composition function as "Modelsubword". Non-hybrid models are denoted as as "Modelvanilla". The "FastTextexternal" is the public available FastText embeddings, which are trained on the full Wikipedia corpus. We also test the version where OOV words are expanded, and denote as "Model+OOV".
Implementation
We implemented all the subword-level models using Chainer deep learning framework. All the code are available in the Vecto project.
Sample script for training word-level word embeddings:
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out
Sample script for training subword-level word embeddings (FastText, Summation):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword sum
Sample script for training subword-level word embeddings (CNN):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword cnn1d`
Sample script for training subword-level word embeddings (Bi-directional LSTM):
python3 -m vecto.embeddings.train_word2vec --path_corpus $path_corpus --path_out $path_out --subword bilstm
Footnotes
- 1
-
Mikolov, T., Yih, W., & Zweig, G. (2013). Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL-HLT 2013 (pp. 746–751). Atlanta, Georgia, 9–14 June 2013. Retrieved from https://www.aclweb.org/anthology/N13-1090
- 2
-
Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching Word Vectors with Subword Information. Transactions of the Association for Computational Linguistics, 5, 135-146. http://www.aclweb.org/anthology/Q17-1010
- 3
-
Li, B., Drozd, A., Liu, T., & Du, X. (n.d.). Subword-level Composition Functions for Learning Word Embeddings. In Proceedings of the Second Workshop on Subword/Character LEvel Models (pp. 38–48). New Orleans, Louisiana, June 6, 2018. http://www.aclweb.org/anthology/W18-1205