Subword-level word embeddings
Motivation
Word-level word embedding models consider word as smallest unit, and often ignores the morphology information.
Word-level word embedding models could not assign meaningful vectors to out-of-vocabulary (OOV) words.
FastText (summation composition function)
FastText is probably the most influential and effective recent model. It represents each word as a bag-of-character n-grams. Representations for character n-grams, once they are learned, can be combined (via simple summation) to represent out-of-vocabulary (OOV) words.
More details about FastText can be found here Link
CNN and RNN subword-level composition functions
We contribute to the discussion of composition functions for constructing subword-level embeddings. We propose CNN- and RNN-based subword-level word embedding models, which can embed arbitrary character sequences into vectors.
We also propose a hybrid training scheme, which makes these neural networks directly integrated into Skip-Gram model. We train two sets of word embeddings simultaneously: one is from a lookup table as in traditional Skip-Gram, and another is from convolutional or recurrent neural network. The former is better at capturing semantic similarity. The latter is more focused on morphology and can learn embeddings for OOV words.
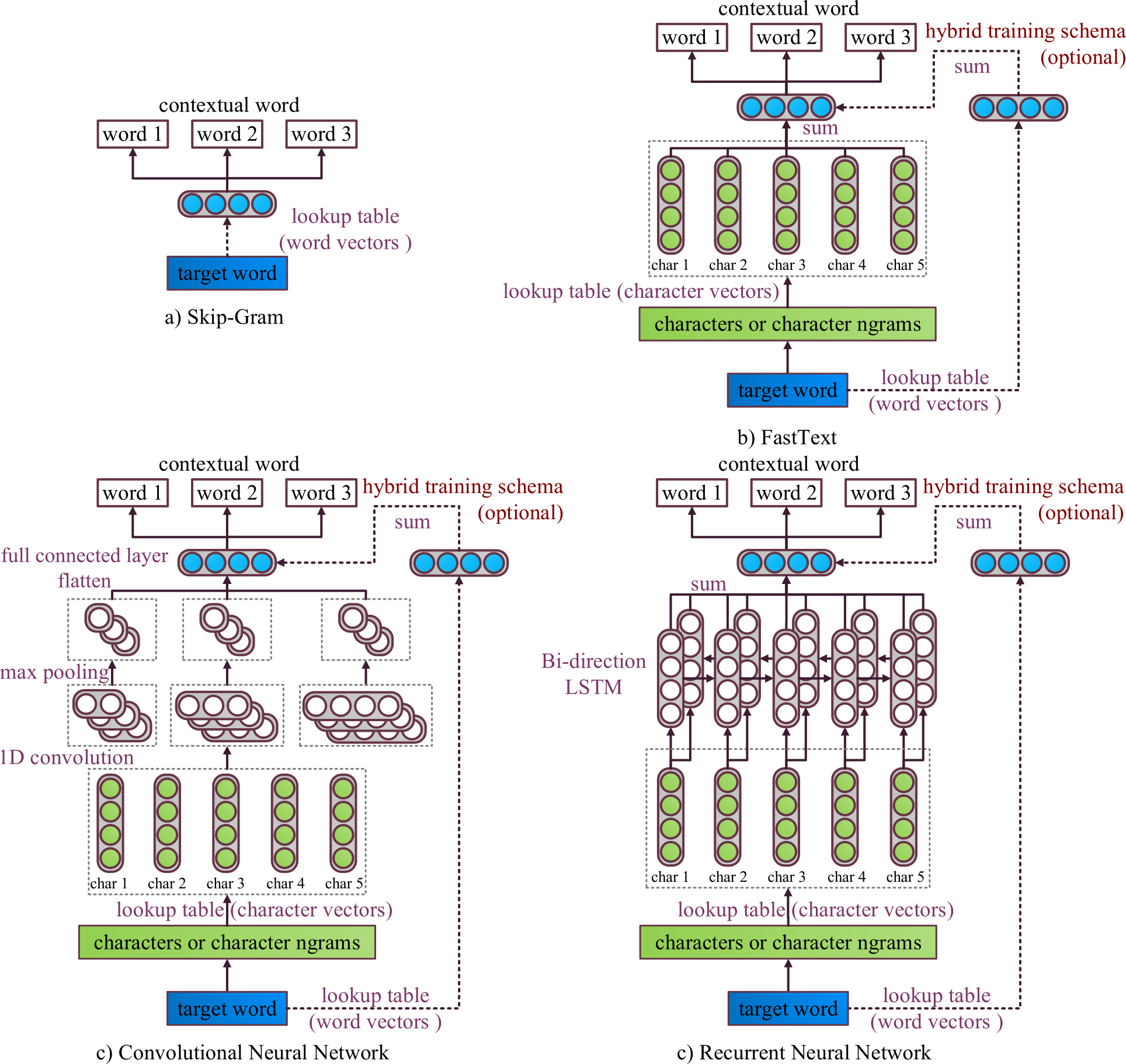
The overall achitecture of the original Skip-Gram, FastText, and our subword-level models are shown in the above figure.
Japanese subword-level embeddings
We also implement the subword-level composition functions to Japanese.
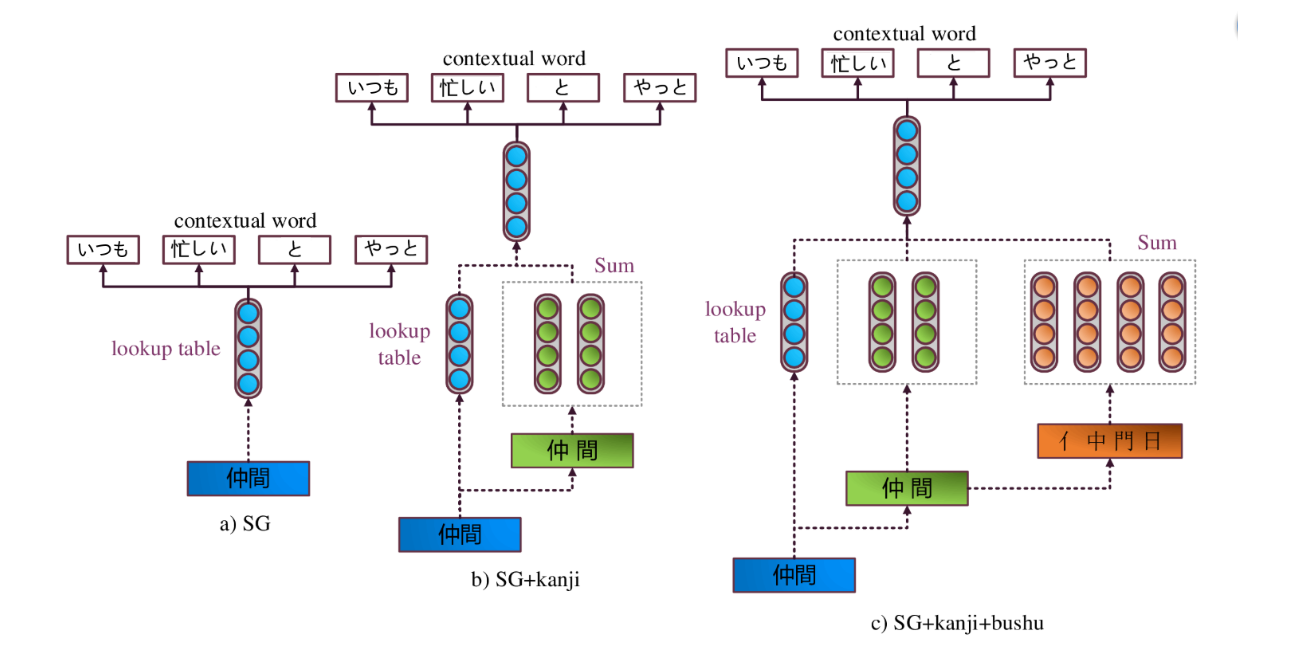
The overall achitecture of Japanese embedding models are shown in the above figure. For Japanese language, We investigate the effect of explicit inclusion of kanjis and kanji components (bushu).

Usage
We implement all the subword-level models (including FastText) using Chainer deep learning framework.
Sample script for training word-level word embeddings:
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/
Sample script for training subword-level word embeddings (FastText):
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword sum
Sample script for training subword-level word embeddings (CNN):
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword cnn1d
Sample script for training subword-level word embeddings (Bi-directional LSTM):
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword bilstm
Sample script for training Japanese word-level word embeddings:
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword none --language jap
Sample script for training Japanese subword-level word embeddings (word+kanji):
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword sum --language jap
Sample script for training Japanese subword-level word embeddings (word+kanji):
> python3 -m vecto.embeddings.train_word2vec --path_corpus path_corpus --path_out /tmp/vecto/embeddings/ --subword sum --language jap --path_word2chars path_word2chars
Experiments
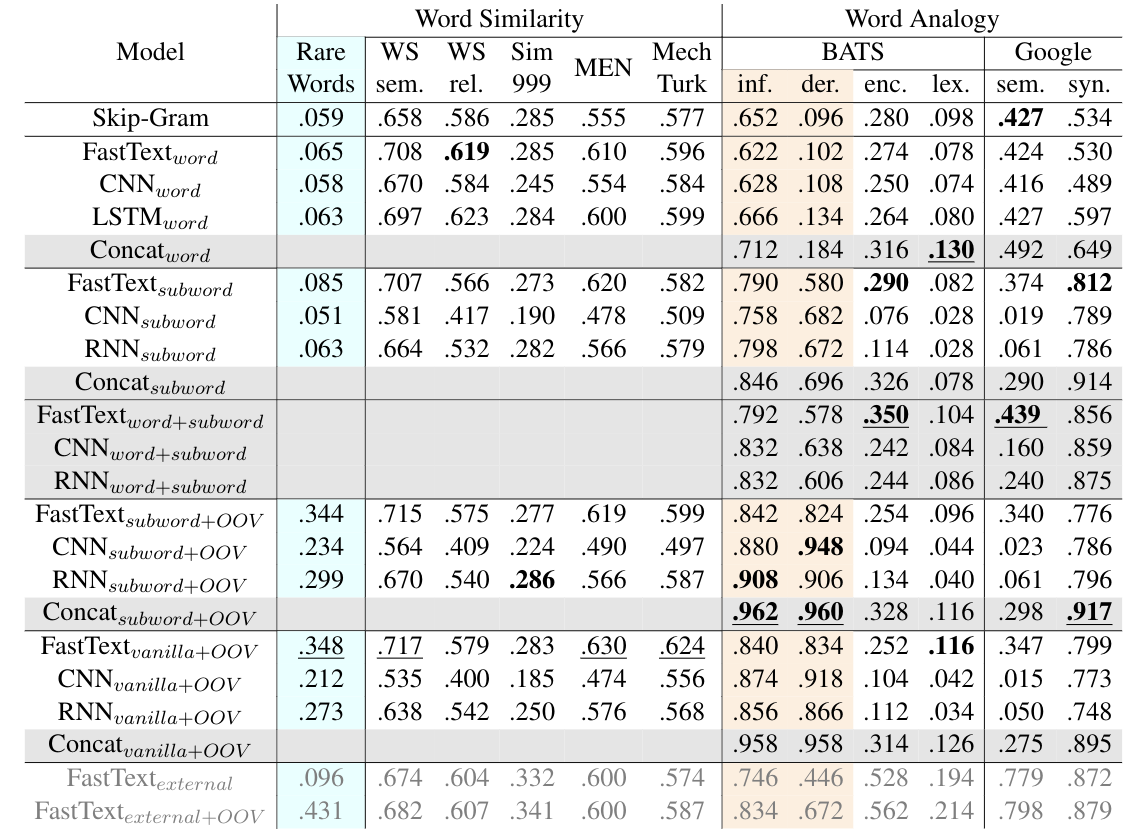
Results on word similarity and word analogy datasets. For hybrid training scheme, we denote the embeddings that come from word vector lookup table as "Model_word", and the embeddings which come from the composition function as "Model_subword". We denote the vanilla (non-hybrid) models as "Model_vanilla". The "FastText_external" is the public available FastText embeddings, which are trained on the full Wikipedia corpus. We also test the version where OOV words are expanded, and denote as "Model+OOV". Model combinations are denoted as gray rows, and best results among them are marked Bold. Rare words dataset in blue column have 43.3% OOV rate, while other word similarity datasets have maximum 4.6% OOV rate. Morphology related categories are denoted as almond columns.
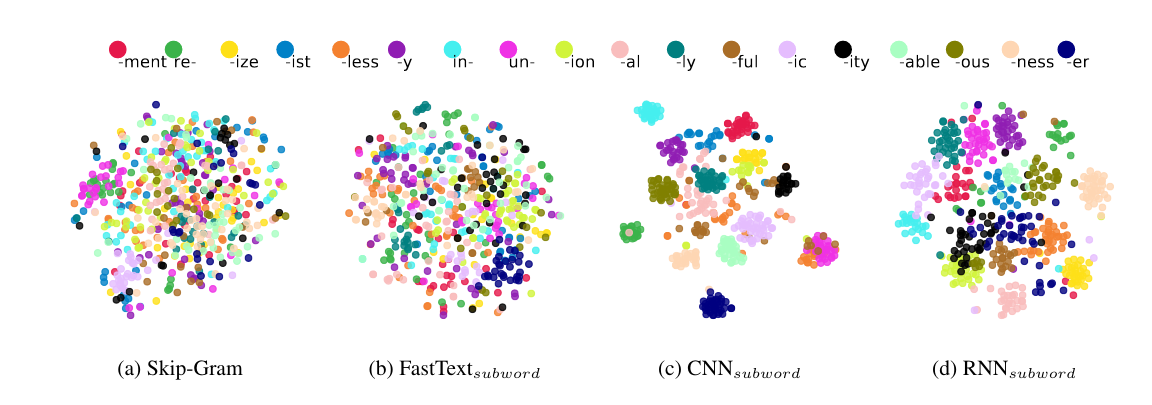
Visualization of learned word embeddings, each dot represents a word, different colors represent different affixes. We use t-SNE to project the word vectors from 300 dimension to 2 dimension.
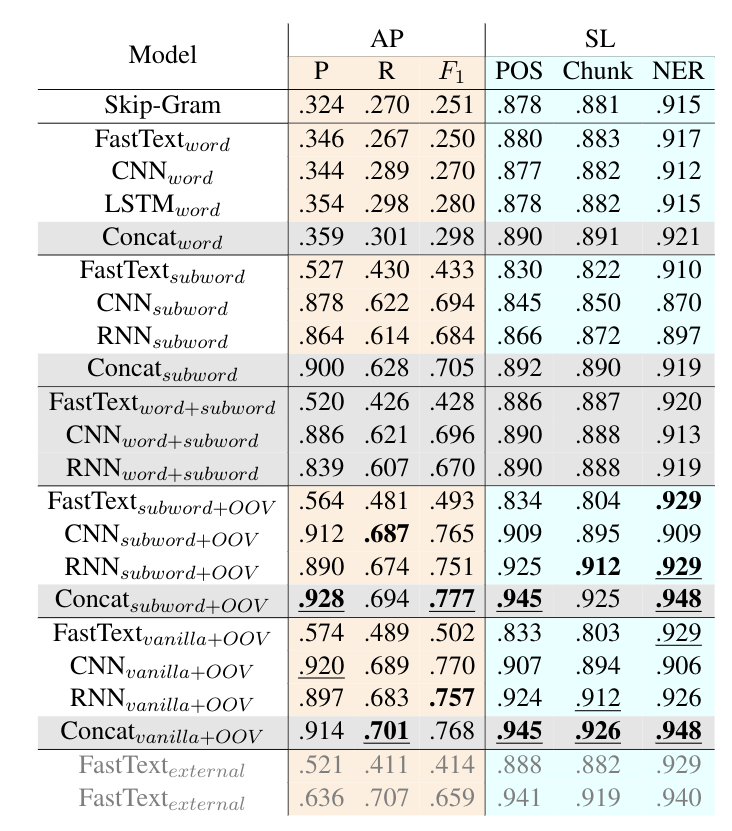
Results on affix prediction (AP) and sequence labeling (SL) tasks. Sequence labeling tasks have 16.5%, 27.1%, 28.5% OOV rate respectively.
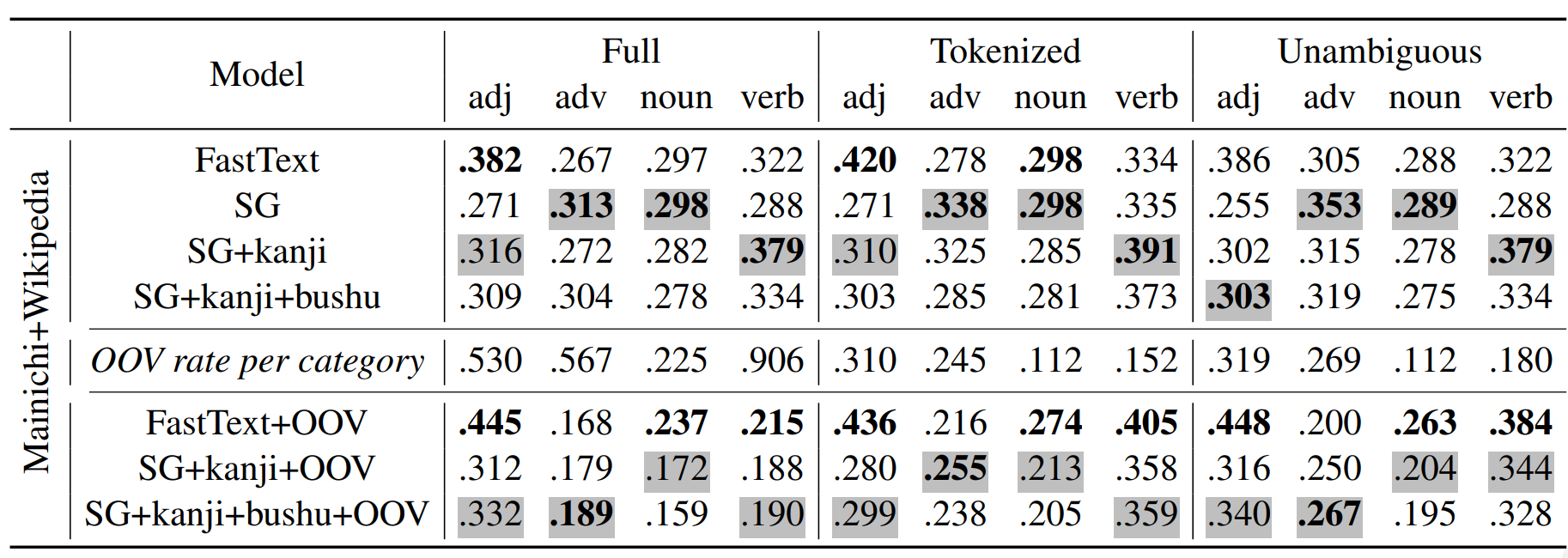
Spearman's correlation with human similarity judgements.
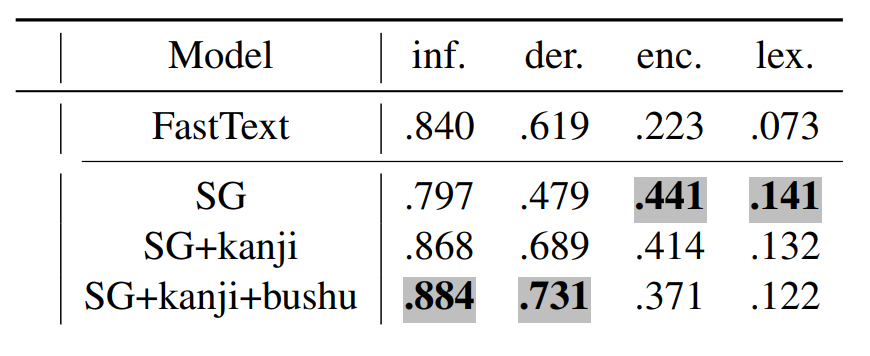
Word analogy task accuracy (LRCos).
Pre-trained embeddings
Please refer to the following page Link